稀疏矩阵的压缩存储 概念、方法与实现
在科学与工程计算、机器学习、图形学等众多领域中,矩阵是一种基础且重要的数据结构。当矩阵中非零元素(或特定值元素)的数量远少于零元素(或默认值元素)的数量时,我们称之为“稀疏矩阵”。例如,一个1000×1000的矩阵中,可能只有不到1%的元素是非零的。如果使用传统的二维数组来存储这样的矩阵,将浪费大量的存储空间来存放零值,并且在运算时也会进行大量无效的零值操作,效率低下。因此,针对稀疏矩阵,发展出了一系列高效的压缩存储方法。
一、 稀疏矩阵的定义与特性
稀疏矩阵没有严格的数学定义。通常,当一个矩阵的稀疏度(非零元素个数与总元素个数的比值)低于一个经验阈值(例如5%或0.5%)时,就可以认为是稀疏的。其核心特性是:
- 大量重复值:绝大多数元素是相同的(通常是零)。
- 分布不规则:非零元素在矩阵中的位置没有固定的规律。
正是这些特性,使得我们可以放弃存储每一个元素,转而只存储非零元素的值及其位置信息,从而达到压缩的目的。
二、 主要的压缩存储方法
1. 三元组顺序表(COO - Coordinate Format)
这是最直观的压缩方法。我们使用三个一维数组来分别存储:
data:所有非零元素的值。row:每个非零元素对应的行号(从0或1开始)。col:每个非零元素对应的列号。
示例:
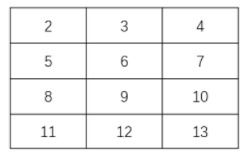
对于一个矩阵:
[ 1 0 0 ]
[ 0 0 5 ]
[ 0 2 0 ]
其三元组表示为(假设行、列索引从0开始):data = [1, 5, 2]row = [0, 1, 2]col = [0, 2, 1]
优点:结构简单,容易构造,适用于非零元素随机分布的矩阵。
缺点:不便于进行矩阵运算(如转置、乘法),因为访问特定行或列需要遍历整个数组。
2. 压缩稀疏行(CSR - Compressed Sparse Row)
这是最常用、最高效的通用稀疏矩阵存储格式之一。它同样使用三个数组:
data:所有非零元素的值,按行优先顺序排列。indices:每个非零元素对应的列号。indptr(或row_ptr):行指针数组。其长度为行数+1。indptr[i]表示第i行第一个非零元素在data和indices中的起始索引,indptr[i+1]是其结束索引。因此,第i行的非零元素存储在data[indptr[i]: indptr[i+1]]中。
示例(同上矩阵):data = [1, 5, 2] // 第一行的1,第二行的5,第三行的2indices = [0, 2, 1] // 分别对应的列号indptr = [0, 1, 2, 3] // 第0行从索引0开始(有1个元素),第1行从索引1开始(有1个元素),第2行从索引2开始(有1个元素),结束于3。
优点:高效支持按行访问、矩阵-向量乘法等操作。内存访问模式连续,缓存友好。
缺点:构建和修改(插入/删除非零元)成本较高。
3. 压缩稀疏列(CSC - Compressed Sparse Column)
CSC是CSR的列优先版本,原理完全相同,只是将“行”换成了“列”。它使用:
data:所有非零元素的值,按列优先顺序排列。indices:每个非零元素对应的行号。indptr:列指针数组。
优点:高效支持按列访问、向量-矩阵乘法、矩阵转置(CSR转CSC即相当于转置)等操作。
三、 专用格式
除了上述通用格式,还有一些针对特殊稀疏模式的格式:
- 对角线存储(DIA):适用于非零元素集中分布在主对角线及其附近几条对角线上的矩阵(如某些偏微分方程离散化产生的矩阵)。
- ELLPACK(ELL):适用于每行非零元素数量大致相同的GPU计算。
- 块压缩存储(BSR):当非零元素呈小块状聚集时,将每个小块视为一个“元素”进行存储,可以提高缓存利用率和特定运算性能。
四、 应用与库支持
在编程实践中,我们通常不会手动实现这些结构,而是使用成熟的科学计算库:
- SciPy(Python):
scipy.sparse模块提供了coo<em>matrix,csr</em>matrix,csc<em>matrix,dia</em>matrix等多种格式,并能高效地进行转换和运算。 - Eigen(C++):提供了稀疏矩阵模块。
- MATLAB:内置了稀疏矩阵类型及相关算法。
五、
稀疏矩阵的压缩存储是平衡空间与时间效率的关键技术。选择哪种格式取决于:
- 矩阵的非零模式(行变化大、列变化大、对角线、块状?)。
- 主要的操作类型(频繁按行访问、按列访问、转置、构建?)。
- 硬件平台(CPU/GPU?对缓存是否敏感?)。
理解这些核心格式的原理,有助于我们在处理大规模稀疏数据时,选择合适的工具和策略,从而设计出高效、节省内存的算法与程序。
如若转载,请注明出处:http://www.ctezn.com/product/24.html
更新时间:2026-06-19 00:48:07